netty.md 11 KB
title: push 推送服务 date: 2019-07-12 15:20:53 tags: [java, netty]
categories: [java, netty]
需求
实现客户端和服务端的tcp长链接通信 完成数据交换
基础功能
- 动态调整服务端设置提高性能
- 心跳检测
- 闲时检测 清除或处理长时间无响应客户端
- 自动编/解码
- 自定义数据包编码 实现 256 种操作的解析(可拓展)
- 支持任意类型数据的发送,配合操作解析
- 基于JWT 的登录认证
- 授权检查,清除未授权客户端
- 消息确认ACK
- 非主动下线的断线检测与重连
- 支持客户端查询与下线等操作
- 微服务化 支持其他服务动态调用
- 支持websocket
- 支持多种序列化方式(现暂json)
- ssl 通道加密 保证数据安全
- data数据加密 保证数据安全
- ID 规则设计 便于后期分布式拓展
- session信息持久化或缓存
- 异常监控 便于错误发现
- 日志 便于错误处理
- 线程池 提高执行效率 缓解通道压力
- 数据压缩 提高传输效率
阻塞IO
缺点:
- 系统资源消耗大,对于线程的使用不够灵活,同一时刻有大量线程处于阻塞状态
- 线程切换效率低
- 数据读写是以字节流为单位,需要自行存储数据
原生NIO
避免了BIO的缺点,线程数量大大降低,线程切换效率提高,使用缓存Buffer 为单位
Netty
Netty 封装了 JDK 的 NIO ,避免复杂的原生操作。
优点:
- Netty 底层IO 随意切换,可以自行段子 NIO 或者 IO 模型
- Netty 自带拆解包,异常回调 ,只用关心相关业务逻辑
- Netty 优化了很多JDK bug 和 操作
- 社区活跃,大多数中间件都涉及Neety 稳定性可靠
- 通道建立和通信
final ServerBootstrap serverBootstrap = new ServerBootstrap();
//接受连接
NioEventLoopGroup boss = new NioEventLoopGroup();
//异步非阻塞处理数据
NioEventLoopGroup worker = new NioEventLoopGroup();
serverBootstrap.group(boss, worker)
//指定我们服务端的 IO 模型为NIO
.channel(NioServerSocketChannel.class)
// 临时存放已完成三次握手的请求的队列的最大长度 如果连接建立频繁,服务器处理创建新连接较慢,可以适当调大这个参数
.option(ChannelOption.SO_BACKLOG, 1024)
// TCP 心跳机制 true 开启
.childOption(ChannelOption.SO_KEEPALIVE, true)
// 是否关闭Nagle算法 true 高实时性,有消息立即发送 false 减少发送次数减少网络交互 提升性能(Nagle 算法)
.childOption(ChannelOption.TCP_NODELAY, true)
//指定启动前的逻辑操作
.handler(new ChannelInitializer<NioServerSocketChannel>() {
@Override
protected void initChannel(NioServerSocketChannel ch) throws Exception {
System.out.println("服务端启动中");
}
})
//用于指定处理新连接数据
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) {
// 闲时检测
ch.pipeline().addLast(new IMIdleStateHandler());
// 非法数据处理
ch.pipeline().addLast(new Spliter());
// 数据编解码编码处理
ch.pipeline().addLast(PacketCodecHandler.INSTANCE);
// 登录信息处理
ch.pipeline().addLast(LoginRequestHandler.INSTANCE);
// 心跳数据处理
ch.pipeline().addLast(HeartBeatRequestHandler.INSTANCE);
// 授权数据处理
ch.pipeline().addLast(AuthHandler.INSTANCE);
// 消息确认信息处理
ch.pipeline().addLast(ConfirmRequestHandler.INSTANCE);
}
});
bind(serverBootstrap, PORT);
通过 NioEventLoopGroup 生成两个线程组,boss 用于捷径worker用于用于处理每一条连接数据读写。使用ServerBootstrap引导设置相关信息,group设置线程组,channel 指定IO 模型,主要的childHandler方法实现NIO的抽象方法,这里面也是实现数据处理的主要逻辑
- ByteBuf 介绍

Netty 中以 ByteBuf 为单位进行数据交换。
ByteBuf 是一个字节容器,容器里面的的数据分为三个部分,第一个部分是已经丢弃的字节,这部分数据是无效的;第二部分是可读字节,这部分数据是 ByteBuf 的主体数据, 从 ByteBuf 里面读取的数据都来自这一部分;最后一部分的数据是可写字节,所有写到 ByteBuf 的数据都会写到这一段。最后一部分虚线表示的是该 ByteBuf 最多还能扩容多少容量
以上三段内容是被两个指针给划分出来的,从左到右,依次是读指针(readerIndex)、写指针(writerIndex),然后还有一个变量 capacity,表示 ByteBuf 底层内存的总容量
从 ByteBuf 中每读取一个字节,readerIndex 自增1,ByteBuf 里面总共有 writerIndex-readerIndex 个字节可读, 由此可以推论出当 readerIndex 与 writerIndex 相等的时候,ByteBuf 不可读
写数据是从 writerIndex 指向的部分开始写,每写一个字节,writerIndex 自增1,直到增到 capacity,这个时候,表示 ByteBuf 已经不可写了
ByteBuf 里面其实还有一个参数 maxCapacity,当向 ByteBuf 写数据的时候,如果容量不足,那么这个时候可以进行扩容,直到 capacity 扩容到 maxCapacity,超过 maxCapacity 就会报错
- 编码和数据
设计属于自己程序的编码格式,使得客户端和服务端共同使用

首先,第一个字段是魔数,通常情况下为固定的几个字节(我们这边规定为4个字节)。 为什么需要这个字段,而且还是一个固定的数?假设我们在服务器上开了一个端口,比如 80 端口,如果没有这个魔数,任何数据包传递到服务器,服务器都会根据自定义协议来进行处理,包括不符合自定义协议规范的数据包。例如,我们直接通过
http://服务器ip来访问服务器(默认为 80 端口), 服务端收到的是一个标准的 HTTP 协议数据包,但是它仍然会按照事先约定好的协议来处理 HTTP 协议,显然,这是会解析出错的。而有了这个魔数之后,服务端首先取出前面四个字节进行比对,能够在第一时间识别出这个数据包并非是遵循自定义协议的,也就是无效数据包,为了安全考虑可以直接关闭连接以节省资源。在 Java 的字节码的二进制文件中,开头的 4 个字节为0xcafebabe用来标识这是个字节码文件,亦是异曲同工之妙接下来一个字节为版本号,通常情况下是预留字段,用于协议升级的时候用到,有点类似 TCP 协议中的一个字段标识是 IPV4 协议还是 IPV6 协议,大多数情况下,这个字段是用不到的,不过为了协议能够支持升级,我们还是先留着
第三部分,序列化算法表示如何把 Java 对象转换二进制数据以及二进制数据如何转换回 Java 对象,比如 Java 自带的序列化,json,hessian 等序列化方式
第四部分的字段表示指令,关于指令相关的介绍,我们在前面已经讨论过,服务端或者客户端每收到一种指令都会有相应的处理逻辑,这里,我们用一个字节来表示,最高支持256种指令,对于我们这个 IM 系统来说已经完全足够了
接下来的字段为数据部分的长度,占四个字节
最后一个部分为数据内容,每一种指令对应的数据是不一样的,比如登录的时候需要用户名密码,收消息的时候需要用户标识和具体消息内容等等
- pipeline 和 channelHandler
- ChannelInboundHandler
处理读数据的逻辑,比如,我们在一端读到一段数据,首先要解析这段数据,然后对这些数据做一系列逻辑处理,最终把响应写到对端, 在开始组装响应之前的所有的逻辑,都可以放置在 ChannelInboundHandler 里处理,它的一个最重要的方法就是 channelRead()。读者可以将 ChannelInboundHandler 的逻辑处理过程与 TCP 的七层协议的解析联系起来,收到的数据一层层从物理层上升到我们的应用层
- ChannelOutBoundHandler
处理写数据的逻辑,它是定义我们一端在组装完响应之后,把数据写到对端的逻辑,比如,我们封装好一个 response 对象,接下来我们有可能对这个 response 做一些其他的特殊逻辑,然后,再编码成 ByteBuf,最终写到对端,它里面最核心的一个方法就是 write(),读者可以将 ChannelOutBoundHandler 的逻辑处理过程与 TCP 的七层协议的封装过程联系起来,我们在应用层组装响应之后,通过层层协议的封装,直到最底层的物理层
#### 传播

两种类型的 handler 在一个双向链表里,但是这两类 handler 的分工是不一样的,inBoundHandler 的事件通常只会传播到下一个 inBoundHandler,outBoundHandler 的事件通常只会传播到下一个 outBoundHandler,两者相互不受干扰。
ctx.writeAndFlush()是从 pipeline 链中的当前节点开始往前找到第一个 outBound 类型的 handler 把对象往前进行传播,如果这个对象确认不需要经过其他 outBound 类型的 handler 处理,就使用这个方法ctx.channel().writeAndFlush()是从 pipeline 链中的最后一个 outBound 类型的 handler 开始,把对象往前进行传播,如果你确认当前创建的对象需要经过后面的 outBound 类型的 handler,那么就调用此方法
对比可知:在某个 inBound 类型的 handler 处理完逻辑之后,调用 ctx.channel().writeAndFlush(),对象会从最后一个 outBound 类型的 handler 开始,逐个往前进行传播,路径是要比 ctx.writeAndFlush() 要长的,使用编解码的话 直接使用ctx.writeAndFlush() 而不需要考虑场景
ID 生成
雪花算法 &
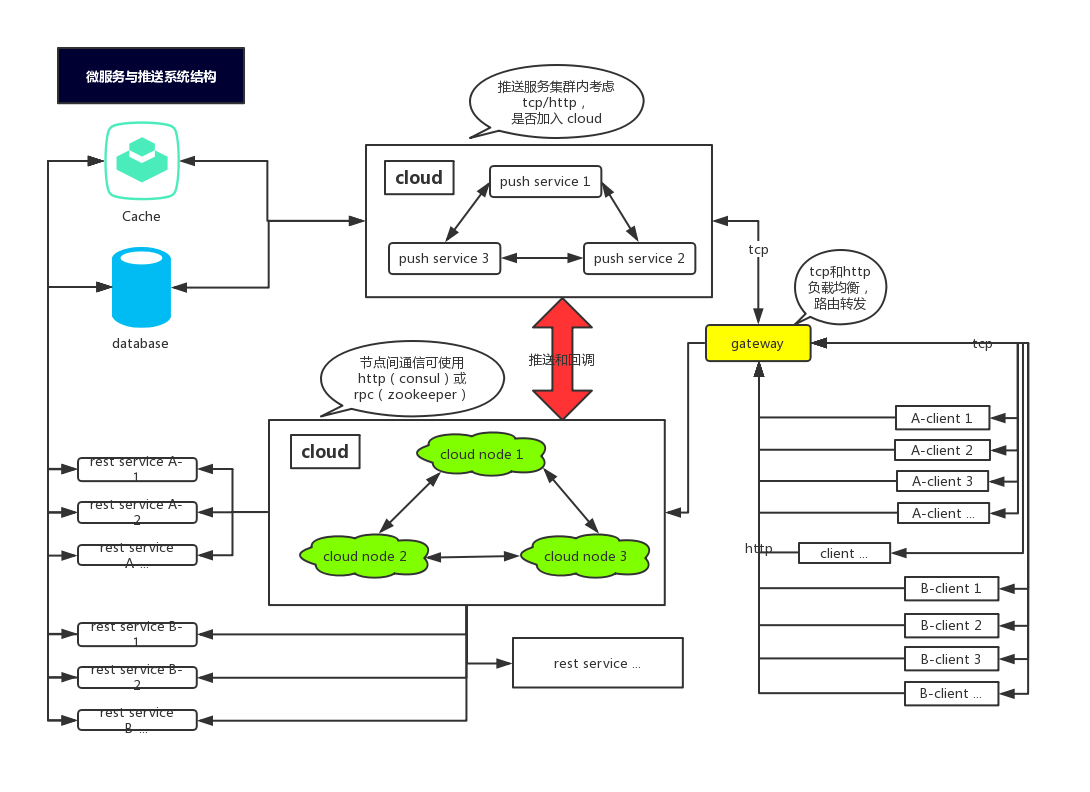
架构图